from pyspark.sql import SparkSession
import pandas as pd
import yamlPySpark SQL Example using Docker
I will take the IBMD movies extracted from Tableau for this project and push the data to my SQL server. Once this is complete, the next step is to pull in data for Quentin Tarantino. This will solve the slowness issues in Tableau. Pyspark will be used to perform the ETL. The tools that I’ll be using are docker and pgAdmin(SQL) for a database. We will need a jupyter/pyspark-notebook container and a PostgreSQL container for docker. These will be connected to a network for further isolation. This project aims to move a large dataset to a database and then build a tableau workbook. The workbook will deliver significant trends discovered.
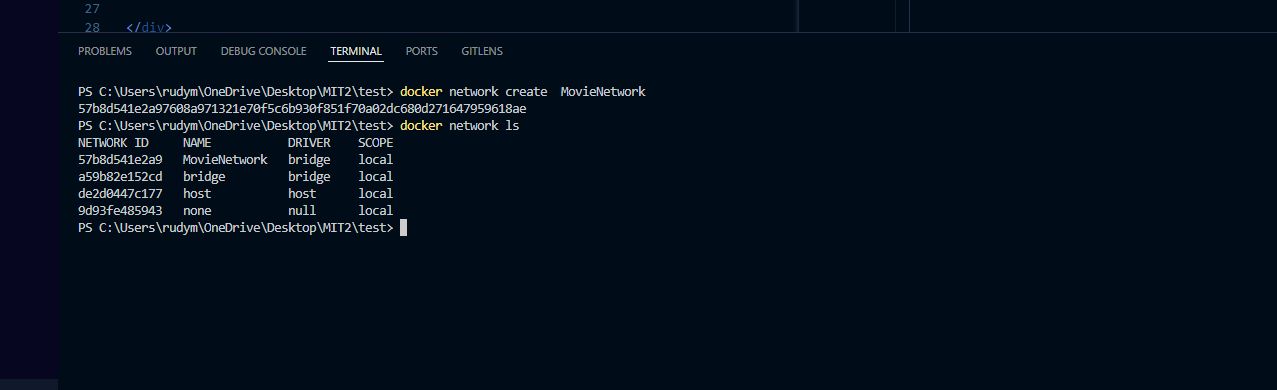
Create Movie Network
This network MovieNetwork will be created in VS Code. The containers will be connected to this network.
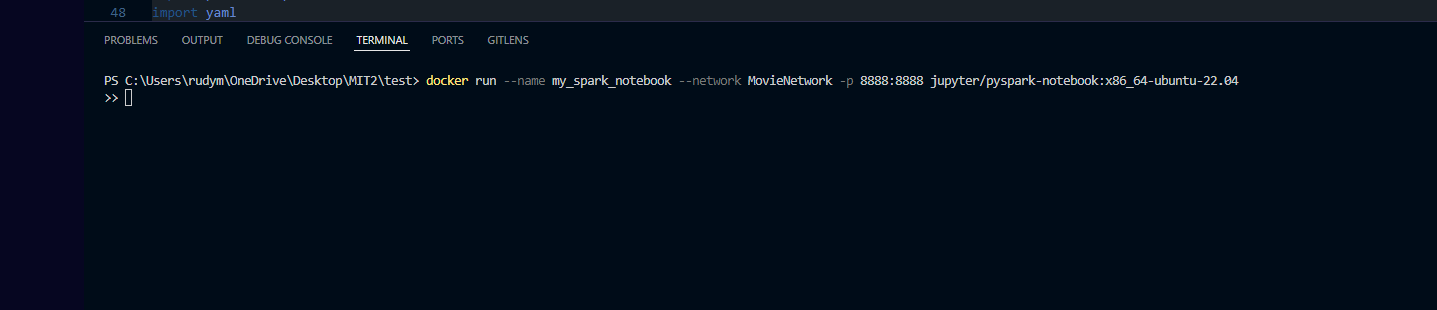
Pull Docker Images
The jupyternotebook/pyspark image is the first to pull. Followed by the postgres image. These will both be tied to the MovieNetwork and have port numbers for the container and host. The reason the jupyernotebook and pysaprk image are combined is to be able to connect to the jupyter kernel inside the docker container. Then VS Code can use the kernel and use Spark through the Pyspark API.
First image is Jupyter Notebooks and Pyspark:
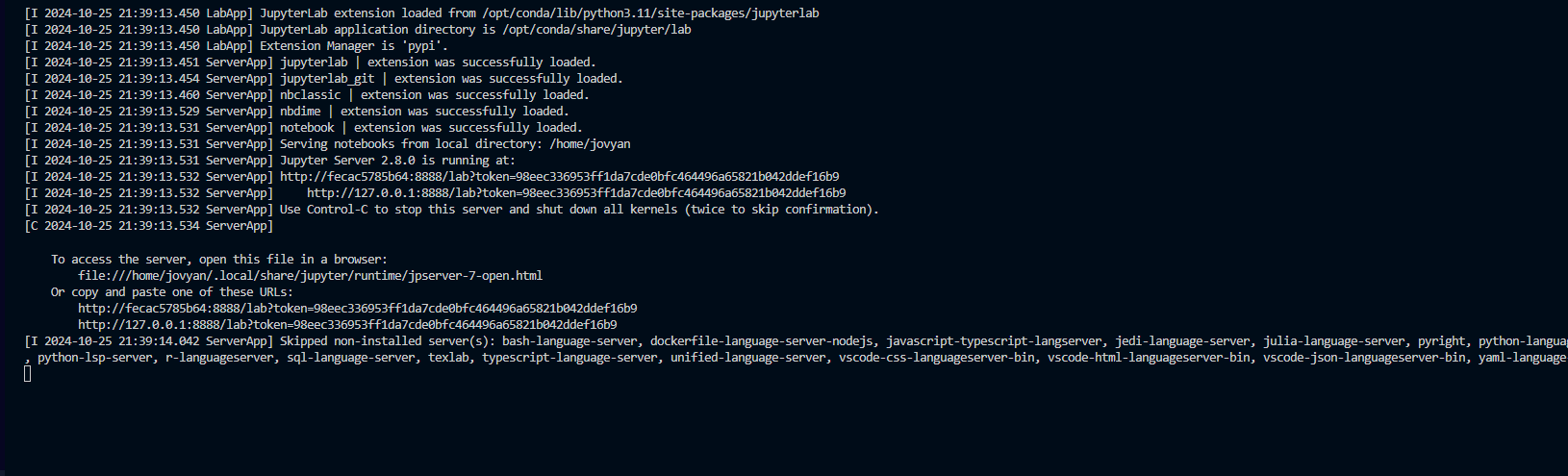
The first container from above is the jupyter notebook/Pyspark container. This runs on a local server with the given port connection. The localhost link will be used in VS Code as a new kernel to connect to and run python and pyspark. Any of the urls should work. It’s best to connect in browser first to make sure jupyternotebook opens up.
Next is PostgreSQL:

The final container is the PostgreSQL container. This has two different ports. One for the container and one for pgAdmin. The data will be pushed to pgAdmin.
And…..Docker
all containers are running and ready!!
IMBD Dataset and SQL Driver
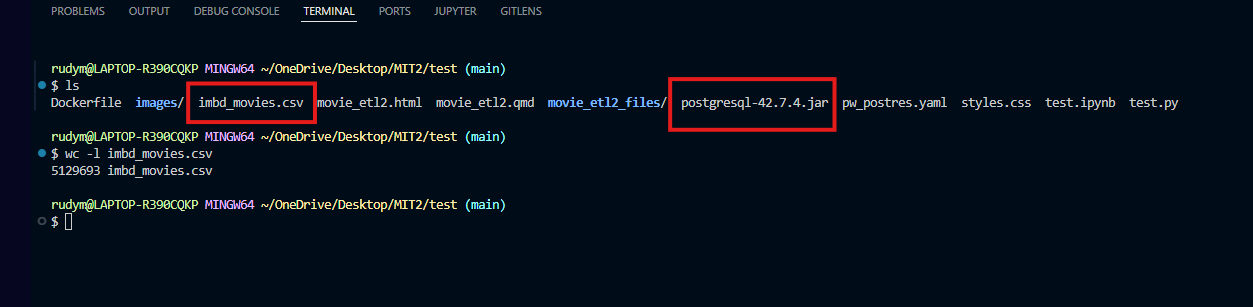
Next, we need to push the data (imbd_movies.csv) and driver (postgresql-42.7.4.jar) into the Pyspark container. This also shows that there are 5,129,693 rows. First, the dataset will be pushed in the :/home/data/ directory. Lastly, the postgresql-42.7.4.jar to the usr/local/spark/jars folder.


We can see that the file movement is a success!! Next, to start up Pyspark.
Load Libraries
Create Spark Session
from pyspark.sql import SparkSession
# Initialize Spark session with extra class path
spark = SparkSession.builder \
.appName("movies_db") \
.config("spark.jars", "/usr/local/spark/jars/postgresql-42.7.4.jar") \
.config("spark.driver.extraClassPath", "/usr/local/spark/jars/postgresql-42.7.4.jar") \
.config("spark.executor.extraClassPath", "/usr/local/spark/jars/postgresql-42.7.4.jar") \
.getOrCreate()
# Path within the Docker container
csv_file = "./imbd_movies.csv"
df = spark.read.csv(csv_file, header=True, inferSchema=True)
# Show the DataFrame
df.createOrReplaceTempView("movies")
# SQL query to select the top 10 movies
top_10_query = "SELECT * FROM movies LIMIT 10"
top_10_df = spark.sql(top_10_query)
# Convert to pandas DataFrame
pandas_df = top_10_df.toPandas()
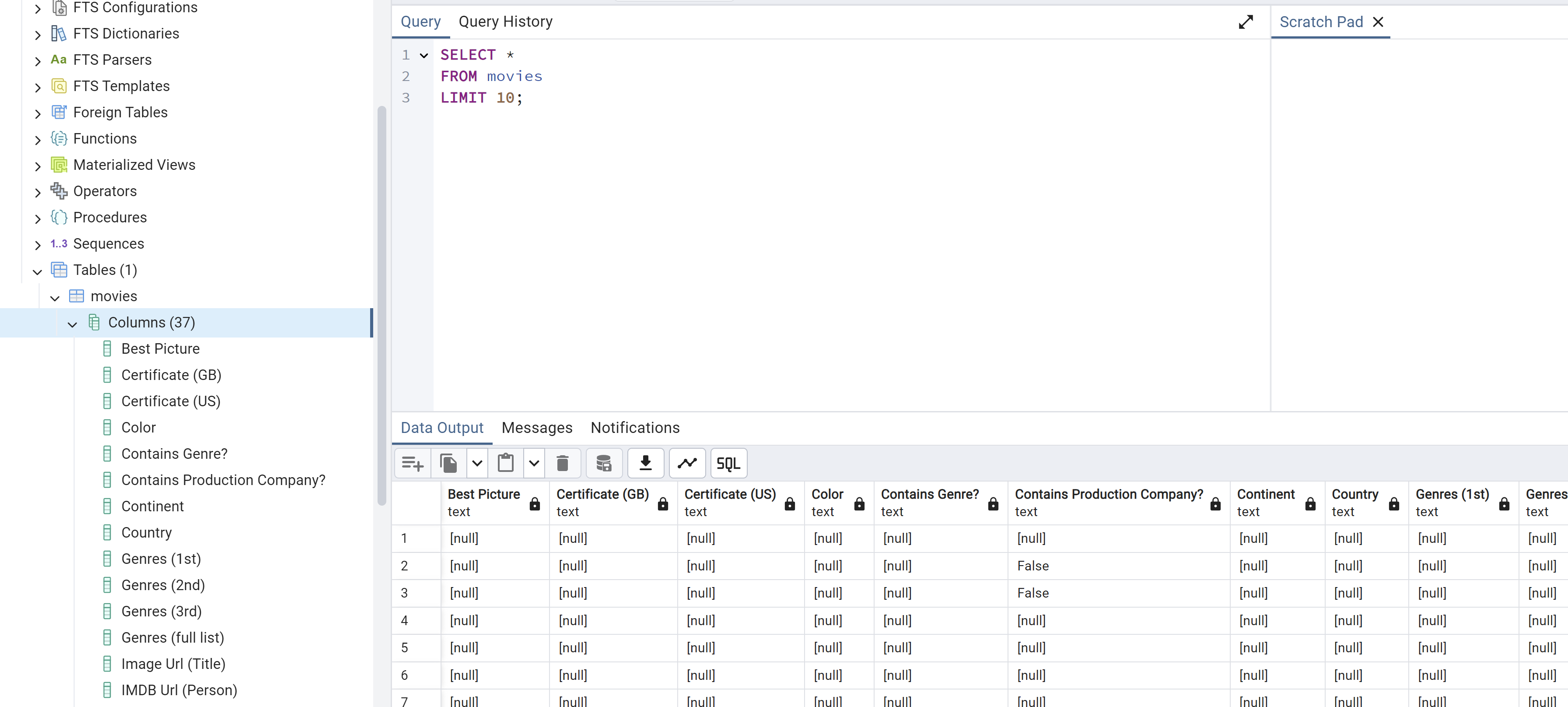
pandas_df| Best Picture | Certificate (GB) | Certificate (US) | Color | Contains Genre? | Contains Production Company? | Continent | Country | Genres (1st) | Genres (2nd) | ... | Title Id | What did they do ? | Who did they play ? | Year of Release | Billing (position in cast list) | IMDB Rating | Number of people | Number of titles | Number Of Votes | Runtime (Minutes) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | None | None | None | None | None | None | None | None | None | ... | tt0193499 | actor | None | 1952 | 1 | None | 1 | 1 | None | None |
| 1 | None | None | None | None | None | False | None | None | None | None | ... | tt0193293 | actor | Lam Tsi-King | 1954 | 1 | None | 1 | 1 | None | None |
| 2 | None | None | None | None | None | False | None | None | None | None | ... | tt0245957 | actor | None | 1961 | 1 | None | 1 | 1 | None | None |
| 3 | None | None | None | None | None | None | None | None | None | None | ... | tt0247371 | actor | Sculptor Martin | 1965 | 1 | None | 1 | 1 | None | None |
| 4 | None | None | None | None | None | None | None | None | None | None | ... | tt0498914 | actor | Jagga | 1992 | 1 | None | 1 | 1 | None | 132 |
| 5 | None | None | None | None | None | None | None | None | None | None | ... | tt6448596 | actor | Sakir | 2007 | 1 | 1.8 | 1 | 1 | 61 | 95 |
| 6 | None | None | None | None | None | None | None | None | None | None | ... | tt0205040 | actor | Ng Chi Keung | 1952 | 2 | None | 1 | 1 | None | None |
| 7 | None | None | None | None | None | None | None | None | None | None | ... | tt0192202 | actor | None | 1953 | 2 | None | 1 | 1 | None | None |
| 8 | None | None | None | None | None | False | None | None | None | None | ... | tt0192049 | actor | None | 1953 | 2 | None | 1 | 1 | None | None |
| 9 | None | None | None | None | None | False | None | None | None | None | ... | tt0193153 | actor | None | 1958 | 2 | None | 1 | 1 | None | None |
10 rows × 37 columns
Write all the data to a DB
# Create a temporary view
df.createOrReplaceTempView("movies")
USERNAME = 'postgres'
PASSWORD = 'mysecretpassword'
# Connection settings
jdbc_url = f"jdbc:postgresql://172.18.0.3:5432/{USERNAME}"
jdbc_properties = {
"user": USERNAME,
"password": PASSWORD,
"driver": "org.postgresql.Driver"
}
# Write test data to PostgreSQL
try:
df.write.jdbc(url=jdbc_url, table="movies", mode="overwrite", properties=jdbc_properties)
print("Data written successfully!")
except Exception as e:
print(f"An error occurred: {e}")Here is the written statement to my local pgAdmin. Below, the dataset is present in the movie_db database. Now, we can subset the data into tableau to make it run faster.